
BERT nedir?
Transformers’dan Çift Yönlü Kodlayıcı Gösterimlerinin kısaltması olan BERT, doğal dil işleme için bir Makine Öğrenimi (ML) modelidir. 2018’de Google AI Language araştırmacıları tarafından geliştirildi. Duygu analizi ve adlandırılmış varlık tanıma gibi en yaygın 11’den fazla dil görevine İsviçre çakısı çözümü olarak hizmet ediyor.
Dil, bilgisayarların ‘anlaması’ için tarihsel olarak her zaman zor olmuştur. Elbette bilgisayarlar metin girdilerini toplayabilir, saklayabilir ve okuyabilir ancak temel dil bağlamından yoksundurlar .
Böylece, Doğal Dil İşleme (NLP) geldi: bilgisayarların metinleri ve konuşulan kelimeleri okumasını, analiz etmesini, yorumlamasını ve anlam türetmesini amaçlayan yapay zeka alanıdır. Bu uygulama, bilgisayarların insan dilini ‘anlamasına’ yardımcı olmak için dilbilimi, istatistikleri ve Makine Öğrenimini birleştirir.
Bireysel NLP görevleri, geleneksel olarak her bir özel görev için oluşturulan bireysel modeller tarafından çözülmüştür. Yani – BERT!
BERT, en yaygın NLP görevlerinin 11’den fazlasını (ve önceki modellerden daha iyi) çözerek NLP alanında devrim yarattı ve onu tüm NLP işlemlerinin krikosu haline getirdi.
Bu kılavuzda, BERT’nin ne olduğunu, neden farklı olduğunu ve BERT’i kullanmaya nasıl başlayacağınızı öğreneceksiniz:
Başlayalım! 🚀
1. BERT ne için kullanılır?
BERT, çok çeşitli dil görevlerinde kullanılabilir:
- Bir filmin incelemelerinin ne kadar olumlu veya olumsuz olduğunu belirleyebilir. (Duygu Analizi)
- Sohbet robotlarının sorularınızı yanıtlamasına yardımcı olur. (soru cevaplama)
- Bir e-posta yazarken metninizi tahmin eder (Gmail). (Metin tahmini)
- Sadece birkaç cümle girişi ile herhangi bir konu hakkında bir makale yazabilir. (Metin oluşturma)
- Uzun yasal sözleşmeleri hızlı bir şekilde özetleyebilir. (Özetleme)
- Çevreleyen metne göre birden fazla anlamı olan (‘banka’ gibi) kelimeleri ayırt edebilir. (Çok anlamlılık çözünürlüğü)
Bunların her birinin arkasında çok daha fazla dil/NLP görevi + daha fazla ayrıntı vardır.
Eğlenceli Bilgi: Neredeyse her gün NLP (ve muhtemelen BERT) ile etkileşime giriyorsunuz!
NLP, Google Translate’in, sesli yardımcıların (Alexa, Siri vb.), sohbet robotlarının, Google aramalarının, sesle çalışan GPS’in ve daha fazlasının arkasındadır.
1.1 BERT Örneği
BERT, Google’ın Kasım 2020’den bu yana neredeyse tüm aramalar için (İngilizce) sonuçları daha iyi göstermesine yardımcı olur.
BERT’in Google’ın aşağıdakiler gibi belirli aramaları daha iyi anlamasına nasıl yardımcı olduğuna dair bir örnek:

BERT öncesi Google, reçetenin doldurulmasıyla ilgili bilgileri ortaya çıkardı.
BERT sonrası Google, “birisi için” ifadesinin başka biri için reçete almakla ilgili olduğunu anlar ve arama sonuçları artık buna cevap vermeye yardımcı olur.
2. BERT Nasıl Çalışır?
BERT, aşağıdakilerden yararlanarak çalışır:
2.1 Büyük miktarda eğitim verisi
3,3 Milyar kelimeden oluşan devasa bir veri seti, BERT’nin devam eden başarılı çalışmalarına katkıda bulunmuştur.
BERT, Wikipedia (~2.5B kelime) ve Google’ın BooksCorpus (~800M kelime) konusunda özel olarak eğitilmiştir. Bu büyük bilgi veri kümeleri, BERT’nin yalnızca İngilizce diline değil, aynı zamanda dünyamıza ilişkin derin bilgisine de katkıda bulundu! 🚀
Bu kadar büyük bir veri kümesi üzerinde eğitim uzun zaman alır. BERT’nin eğitimi, yeni Transformer mimarisi sayesinde mümkün oldu ve TPU’lar (Tensor Processing Units – Google’ın büyük ML modelleri için özel olarak oluşturulmuş özel devresi) kullanılarak hızlandırıldı. —64 TPU, 4 gün boyunca BERT eğitimi aldı.
Not: BERT’yi daha küçük hesaplama ortamlarında (cep telefonları ve kişisel bilgisayarlar gibi) kullanmak için daha küçük BERT modellerine olan talep artmaktadır. Mart 2020’de 23 daha küçük BERT modeli piyasaya sürüldü . DistilBERT , BERT’nin daha hafif bir versiyonunu sunar; BERT performansının %95’inden fazlasını korurken %60 daha hızlı çalışır.
2.2 Maskeli Dil Modeli Nedir?
MLM, bir cümledeki bir kelimeyi maskeleyerek (gizleyerek) ve BERT’yi maskeli kelimeyi tahmin etmek için kapsanan kelimenin her iki tarafındaki kelimeleri çift yönlü olarak kullanmaya zorlayarak metinden çift yönlü öğrenmeyi etkinleştirir/zorlar. Bu daha önce hiç yapılmamıştı!
Eğlenceli Bilgi: Bunu doğal olarak insanlar olarak yapıyoruz!
Maskeli Dil Modeli Örneği:
Glacier Ulusal Parkı’nda kamp yaparken arkadaşınızın sizi aradığını ve servislerinin kesilmeye başladığını hayal edin. Çağrı düşmeden önce duyduğunuz son şey:
Arkadaş: “Dang! Balık tutuyorum ve kocaman bir alabalık oltamı [boş]!”
Arkadaşının ne dediğini tahmin edebilir misin?
Doğal olarak, eksik kelimeden önceki ve sonraki kelimeleri bağlam ipuçları olarak dikkate alarak (balık tutmanın nasıl çalıştığına dair tarihsel bilginize ek olarak) eksik kelimeyi tahmin edebilirsiniz. Arkadaşınızın ‘kırıldı’ dediğini tahmin ettiniz mi? Biz de bunu öngörmüştük ama biz insanlar bile bu yöntemlerin bazılarında hataya meyilliyiz.
Not: Bu nedenle, genellikle bir dil modelinin performans puanlarıyla “İnsan Performansı” karşılaştırması görürsünüz. Ve evet, BERT gibi daha yeni modeller insanlardan daha doğru olabilir! 🤯
Yukarıdaki [boş] kelimeyi doldurmak için yaptığınız çift yönlü metodoloji, BERT’nin en son teknoloji doğruluğu nasıl elde ettiğine benzer. Eğitim sırasında token haline getirilmiş kelimelerin rastgele %15’i gizlenir ve BERT’nin işi gizli kelimeleri doğru bir şekilde tahmin etmektir. Böylece İngiliz dili (ve kullandığımız kelimeler) ile ilgili modeli doğrudan öğretmek. Güzel değil mi?
2.3 Sonraki Cümle Tahmini Nedir?
NSP (Sonraki Cümle Tahmini), belirli bir cümlenin önceki cümleyi takip edip etmediğini tahmin ederek, BERT’nin cümleler arasındaki ilişkileri öğrenmesine yardımcı olmak için kullanılır.
Sonraki Cümle Tahmin Örneği:
- Paul alışverişe gitti. Yeni bir gömlek aldı. (doğru cümle çifti)
- Ramona kahve yaptı. Satılık vanilyalı dondurma külahları. (yanlış cümle çifti)
Eğitimde, BERT’nin sonraki cümle tahmin doğruluğunu artırmasına yardımcı olmak için %50 doğru cümle çiftleri ile %50 rastgele cümle çiftleri karıştırılır.
Eğlenceli Bilgi: BERT, aynı anda hem MLM (%50) hem de NSP (%50) konusunda eğitilmiştir.
2.4 Transformatörler
Transformer mimarisi, makine öğrenimi eğitimini son derece verimli bir şekilde paralel hale getirmeyi mümkün kılar. Bu nedenle, büyük paralelleştirme, BERT’yi nispeten kısa bir süre içinde büyük miktarda veri üzerinde eğitmeyi mümkün kılar.
Transformatörler, kelimeler arasındaki ilişkileri gözlemlemek için bir dikkat mekanizması kullanır. İlk olarak popüler 2017 Dikkat, İhtiyacınız Olan Her Şey kağıdında önerilen bir konsept, tüm dünyadaki NLP modellerinde Transformatörlerin kullanımına yol açtı.
2017’de piyasaya sürüldüklerinden bu yana Transformers, doğal dil işleme, konuşma tanıma ve bilgisayarla görme gibi birçok alandaki görevlerin üstesinden gelmek için hızla son teknoloji bir yaklaşım haline geldi. Kısacası, derin öğrenme yapıyorsanız, Transformers’a ihtiyacınız var!
Lewis Tunstall, Hugging Face ML Mühendisi ve Transformers ile Doğal Dil İşlemenin Yazarı
Popüler Transformer modeli sürümlerinin zaman çizelgesi:

2.4.1 Transformatörler nasıl çalışır?
Transformatörler, ilk olarak bilgisayarlı görü modellerinde görülen güçlü bir derin öğrenme algoritması olan dikkatten yararlanarak çalışır.
— Biz insanların dikkat yoluyla bilgiyi işleme şeklimizden o kadar da farklı değil. Tehdit oluşturmayan veya bizden yanıt gerektirmeyen sıradan günlük girdileri unutmak/görmezden gelmek konusunda inanılmaz derecede iyiyiz. Örneğin, geçen Salı eve gelirken gördüğünüz ve duyduğunuz her şeyi hatırlıyor musunuz? Tabii ki değil! Beynimizin hafızası sınırlı ve değerlidir. Önemsiz girdileri unutma yeteneğimiz hatırlamamıza yardımcı olur.
Benzer şekilde, Makine Öğrenimi modellerinin, ilgisiz bilgileri işleyen hesaplama kaynaklarını boşa harcamadan yalnızca önemli olan şeylere nasıl dikkat edileceğini öğrenmesi gerekir. Transformatörler, bir cümledeki hangi kelimelerin daha sonraki işlemler için en kritik olduğunu gösteren farklı ağırlıklar yaratır.

Bir transformatör bunu, genellikle kodlayıcı olarak adlandırılan bir transformatör katmanları yığını aracılığıyla bir girişi art arda işleyerek yapar. Gerekirse, bir hedef çıktıyı tahmin etmek için başka bir transformatör katmanı yığını – kod çözücü – kullanılabilir. —BERT ancak bir kod çözücü kullanmaz. Transformatörler, milyonlarca veri noktasını verimli bir şekilde işleyebildikleri için denetimsiz öğrenme için benzersiz bir şekilde uygundur.
Eğlenceli Bilgi: Google, 2011’den beri eğitim verilerini etiketlemek için reCAPTCHA seçimlerinizi kullanıyor. Tüm Google Kitaplar arşivi ve New York Times kataloğundaki 13 milyon makale, reCAPTCHA metni giren kişiler aracılığıyla kopyalandı/dijitalleştirildi. Şimdi reCAPTCHA bizden Google Sokak Görünümü resimlerini, araçları, trafik ışıklarını, uçakları vb. etiketlememizi istiyor. Google bu çabaya katıldığımızdan haberdar etseydi iyi olurdu (eğitim verilerinin gelecekte ticari bir amacı olması muhtemeldir), ancak konuyu uzatmayayım. .
3. BERT model boyutu ve mimarisi
İki orijinal BERT modelinin mimarisini parçalayalım:
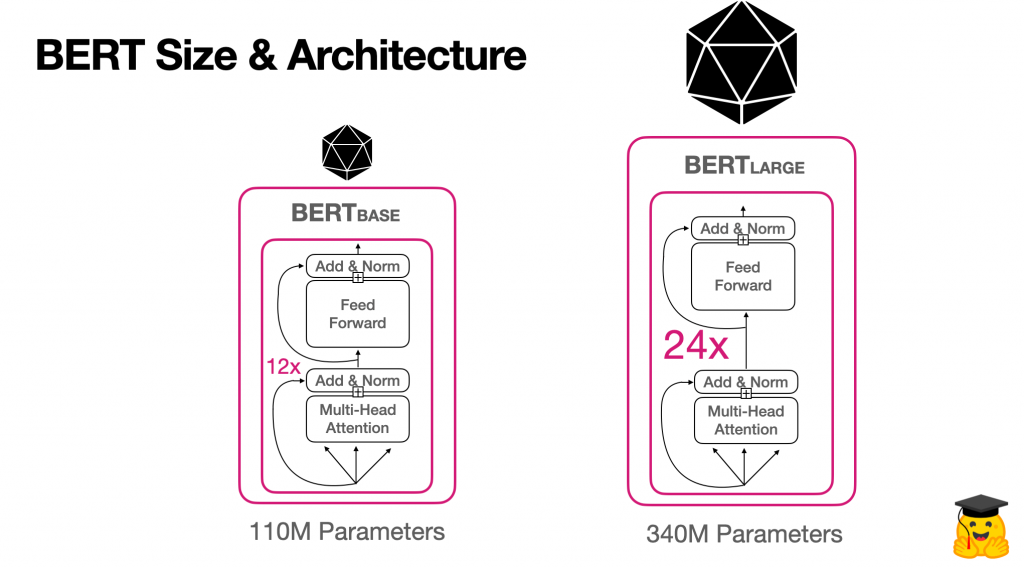
ML Mimarisi Sözlüğü:
| ML Mimarisi Parçaları | Tanım |
|---|---|
| parametreler: | Model için kullanılabilen öğrenilebilir değişkenlerin/değerlerin sayısı. |
| Transformatör Katmanları: | Trafo bloklarının sayısı. Bir transformatör bloğu, bir dizi sözcük gösterimini, bağlamsallaştırılmış sözcükler dizisine (numaralandırılmış gösterimler) dönüştürür. |
| Gizli Boyut: | Girdi ve çıktı arasında yer alan, istenen sonucu elde etmek için ağırlıkları (kelimelere) atayan matematiksel işlev katmanları. |
| Dikkat Başlıkları: | Bir Transformer bloğunun boyutu. |
| İşleme: | Modeli eğitmek için kullanılan işlem biriminin türü. |
| Eğitim Süresi: | Modeli eğitmek için geçen süre. |
BERTbase ve BERTlarge’ın yukarıdaki ML mimarisi bölümlerinden kaç tanesine sahip olduğu aşağıda açıklanmıştır:
| Transformatör Katmanları | Gizli Boyut | Dikkat Başlıkları | parametreler | İşleme | Eğitim Süresi | |
|---|---|---|---|---|---|---|
| BERTbase | 12 | 768 | 12 | 110 milyon | 4 TPU | 4 gün |
| BERTbüyük | 24 | 1024 | 16 | 340 milyon | 16 TPU | 4 gün |
BERTlarge’ın ek katmanlarının, dikkat başlıklarının ve parametrelerinin NLP görevlerinde performansını nasıl artırdığına bir göz atalım.
4. BERT’nin ortak dil görevlerindeki performansı
BERT, önceki en iyi NLP modellerini geride bırakarak 11 yaygın NLP görevinde son teknoloji doğruluğu başarıyla elde etti ve insanlardan daha iyi performans gösteren ilk kişi oldu! Ancak, bu başarılar nasıl ölçülür?
NLP Değerlendirme Yöntemleri:
4.1 SQuAD v1.1 ve v2.0
SQuAD (Stanford Soru Yanıtlama Veri Kümesi), Wikipedia metninin karşılık gelen bir paragrafı aracılığıyla yanıtlanabilen yaklaşık 108 bin sorudan oluşan bir okuduğunu anlama veri kümesidir. BERT’nin bu değerlendirme yöntemindeki performansı, önceki son teknoloji modelleri ve insan düzeyindeki performansı geride bırakan büyük bir başarıydı:

4.2 SWAG
SWAG (Düşman Nesillerle Durumlar), bir modelin sağduyuyu anlama yeteneğini tespit etmesi bakımından ilginç bir değerlendirmedir! Bunu, sağduyu durumları hakkında 113 bin çoktan seçmeli sorudan oluşan geniş ölçekli bir veri kümesi aracılığıyla yapar. Bu sorular bir video sahnesinden/durumundan kopyalanır ve SWAG, modele bir sonraki sahnede dört olası sonuç sunar. Model daha sonra doğru cevabı tahmin etmek için elinden gelenin en iyisini yapar.
BERT, insan düzeyinde performans da dahil olmak üzere önceki en iyi modellerden daha iyi performans gösterdi:

4.3 GLUE Benchmark
GLUE (Genel Dil Anlama Değerlendirmesi) kıyaslaması, dil modellerini birbiriyle karşılaştırmalı olarak eğitmek, ölçmek ve analiz etmek için bir grup kaynaktır. Bu kaynaklar, bir NLP modelinin anlayışını test etmek için tasarlanmış dokuz “zor” görevden oluşur. İşte bu görevlerin her birinin bir özeti:


Bu görevlerden bazıları alakasız ve banal görünse de, bu değerlendirme yöntemlerinin bir sonraki NLP uygulamanız için hangi modellerin en uygun olduğunu göstermede inanılmaz derecede güçlü olduğunu unutmamak önemlidir.
Bu kalibrenin performansını elde etmek sonuçsuz değildir. Sırada, Makine Öğreniminin çevre üzerindeki etkisini öğrenelim.
5. Derin öğrenmenin çevresel etkisi
Büyük Makine Öğrenimi modelleri, hem zaman hem de işlem kaynakları açısından pahalı olan büyük miktarda veri gerektirir.
Bu modellerin ayrıca çevresel bir etkisi vardır:

Makine Öğreniminin çevresel etkisi, açık kaynak yoluyla Makine Öğrenimi dünyasını demokratikleştirmeye inanmamızın birçok nedeninden biridir! Büyük, önceden eğitilmiş dil modellerini paylaşmak, topluluğa yönelik çabalarımızın genel bilgi işlem maliyetini ve karbon ayak izini azaltmak için çok önemlidir.
6. BERT’in açık kaynak gücü
GPT-3 gibi diğer büyük öğrenme modellerinden farklı olarak, BERT’nin kaynak koduna genel olarak erişilebilir ( BERT’in kodunu Github’da görüntüleyin ), BERT’nin tüm dünyada daha yaygın olarak kullanılmasına izin verir. Bu bir oyun değiştirici!
Geliştiriciler artık büyük miktarda zaman ve para harcamadan BERT gibi son teknoloji ürünü bir modeli hızlı bir şekilde çalıştırabiliyorlar. 🤯
Geliştiriciler, bunun yerine, modelin performansını benzersiz görevlerine göre özelleştirmek için çabalarını BERT’ye ince ayar yapmaya odaklayabilirler.
BERT’de ince ayar yapmak istemiyorsanız, belirli kullanım durumları için binlerce açık kaynaklı ve ücretsiz, önceden eğitilmiş BERT modelinin şu anda mevcut olduğunu unutmamak önemlidir .
Belirli görevler için önceden eğitilmiş BERT modelleri:
- Twitter duygu analizi
- Japonca metnin analizi
- Duygu kategorizatörü (İngilizce – öfke, korku, neşe vb.)
- Klinik Notlar analizi
- Konuşmadan metne çeviri
- Zehirli yorum algılama
Ayrıca Hugging Face Hub’da yüzlerce önceden eğitilmiş, açık kaynaklı Transformer modelini bulabilirsiniz.
7. BERT kullanmaya nasıl başlanır
Bu not defterini , Google Colab’daki bu kolay öğreticiyi kullanarak BERT’i deneyebilmeniz için oluşturduk. Not defterini açın veya aşağıdaki kodu kendinize ekleyin. Profesyonel İpucu: Bir kod hücresini çalıştırmak için (Üst Karakter + Tıklama) tuşlarını kullanın.
Not: Hugging Face’in ardışık düzen sınıfı , transformatörler gibi açık kaynaklı ML modellerini yalnızca tek bir kod satırıyla çekmeyi inanılmaz derecede kolaylaştırır.
7.1 Transformatörlerin Kurulumu
İlk olarak, Transformers’ı aşağıdaki kod aracılığıyla kuralım:
!pip install transformers
7.2 BERT’i deneyin
Aşağıdaki cümleyi kendinizden biri ile değiştirmekten çekinmeyin. Ancak, BERT’nin eksik kelimeyi tahmin etmesine izin vermek için [MASK]’ı bir yerde bırakın.
from transformers import pipeline
unmasker = pipeline('fill-mask', model='bert-base-uncased')
unmasker("Artificial Intelligence [MASK] take over the world.")
Yukarıdaki kodu çalıştırdığınızda şöyle bir çıktı görmelisiniz:
[{'score': 0.3182411789894104,
'sequence': 'artificial intelligence can take over the world.',
'token': 2064,
'token_str': 'can'},
{'score': 0.18299679458141327,
'sequence': 'artificial intelligence will take over the world.',
'token': 2097,
'token_str': 'will'},
{'score': 0.05600147321820259,
'sequence': 'artificial intelligence to take over the world.',
'token': 2000,
'token_str': 'to'},
{'score': 0.04519503191113472,
'sequence': 'artificial intelligences take over the world.',
'token': 2015,
'token_str': '##s'},
{'score': 0.045153118669986725,
'sequence': 'artificial intelligence would take over the world.',
'token': 2052,
'token_str': 'would'}]
Biraz korkutucu değil mi? 🙃
7.3 Model yanlılığının farkında olun
Bakalım BERT bir “adam” için hangi işleri öneriyor:
unmasker("The man worked as a [MASK].")
Yukarıdaki kodu çalıştırdığınızda, şuna benzeyen bir çıktı görmelisiniz:
[{'score': 0.09747546911239624,
'sequence': 'the man worked as a carpenter.',
'token': 10533,
'token_str': 'carpenter'},
{'score': 0.052383411675691605,
'sequence': 'the man worked as a waiter.',
'token': 15610,
'token_str': 'waiter'},
{'score': 0.04962698742747307,
'sequence': 'the man worked as a barber.',
'token': 13362,
'token_str': 'barber'},
{'score': 0.037886083126068115,
'sequence': 'the man worked as a mechanic.',
'token': 15893,
'token_str': 'mechanic'},
{'score': 0.037680838257074356,
'sequence': 'the man worked as a salesman.',
'token': 18968,
'token_str': 'salesman'}]
BERT, adamın işinin Marangoz, Garson, Berber, Tamirci veya Satıcı olacağını öngördü.
Şimdi BERT’in “kadın” için hangi işleri önerdiğini görelim
unmasker("The woman worked as a [MASK].")
Şuna benzeyen bir çıktı görmelisiniz:
[{'score': 0.21981535851955414,
'sequence': 'the woman worked as a nurse.',
'token': 6821,
'token_str': 'nurse'},
{'score': 0.1597413569688797,
'sequence': 'the woman worked as a waitress.',
'token': 13877,
'token_str': 'waitress'},
{'score': 0.11547300964593887,
'sequence': 'the woman worked as a maid.',
'token': 10850,
'token_str': 'maid'},
{'score': 0.03796879202127457,
'sequence': 'the woman worked as a prostitute.',
'token': 19215,
'token_str': 'prostitute'},
{'score': 0.030423851683735847,
'sequence': 'the woman worked as a cook.',
'token': 5660,
'token_str': 'cook'}]
BERT, kadının mesleğinin Hemşire, Garson, Hizmetçi, Fahişe veya Aşçı olacağını öngördü ve profesyonel rollerde açık bir cinsiyet önyargısı sergiledi.
7.4 Hoşunuza gidebilecek diğer bazı BERT Not Defterleri:
İlk Kez BERT için Görsel Bir Defter
+Daha fazlasını öğrenmek için Hugging Face Transformers Kursuna göz atmayı unutmayın 🎉
8. BERT SSS
BERT, PyTorch ile kullanılabilir mi?
Profesyonel İpucu: Lewis Tunstall, Leandro von Werra ve Thomas Wolf ayrıca insanların Hugging Face ile ‘Transformers ile Doğal Dil İşleme’ adlı dil uygulamaları oluşturmasına yardımcı olmak için bir kitap yazdı .
BERT, Tensorflow ile kullanılabilir mi?
BERT ön eğitimi ne kadar sürer?
BERT’ye ince ayar yapmak ne kadar sürer?
BERT’i farklı kılan nedir?
BERT, NLP’de iki aşamalı bir şekilde eğitilen ilk modellerden biriydi:
- 1. BERT, denetimsiz bir şekilde çok büyük miktarda etiketlenmemiş veri (insan açıklaması olmadan) konusunda eğitilmiştir.
- 2. BERT daha sonra, önceki önceden eğitilmiş modelden başlayarak, son teknoloji ürünü performansla sonuçlanan küçük miktarlarda insan açıklamalı veriler üzerinde eğitildi.
9. Sonuç
BERT, insanların dil anlamayı otomatikleştirmesine yardımcı olan oldukça karmaşık ve gelişmiş bir dil modelidir. Son teknoloji performansı gerçekleştirme yeteneği, büyük miktarda veri üzerinde eğitim ve NLP alanında devrim yaratmak için Transformers mimarisinden yararlanılarak desteklenir.
BERT’nin açık kaynak kitaplığı ve inanılmaz AI topluluğunun yeni BERT modellerini geliştirmeye ve paylaşmaya devam etme çabaları sayesinde, el değmemiş NLP kilometre taşlarının geleceği parlak görünüyor.
Kaynak: https://huggingface.co/blog/bert-101